Project Showcase
-
Discourse Analysis and Parsing
Distantly- and Self-Supervised Approaches to Infer Discourse
In our recent line of distantly- and self-supervised approaches for RST-style discourse parsing, we aim to generate robust silver-standard discourse trees informed by related downstream tasks.
Discourse from Sentiment Analysis
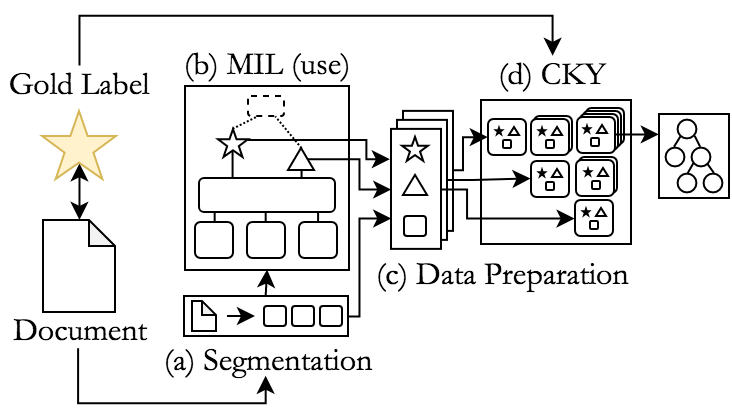
MEGA-DT Disocurse Annotation Pipeline In our EMNLP 2019 and MEGA-DT (published at EMNLP 2020) papers, we propose a combination of a deep multiple instance learning model (MILNet) with the traditional CKY algorithm to generate nuclearity-attributed discourse structures for large-scale sentiment annotated corpora. We show that while the silver-standard discourse trees cannot outperform in-domain supervised discourse parsers, they do capture highly robust structures, which generalize well between domains, reaching the best inter-domain discourse parsing performance to date. Our generated silver-standard discourse treebank containing over 250.000 complete discourse trees in the review domain can be downloaded here.
Discourse from Topic Segmentation
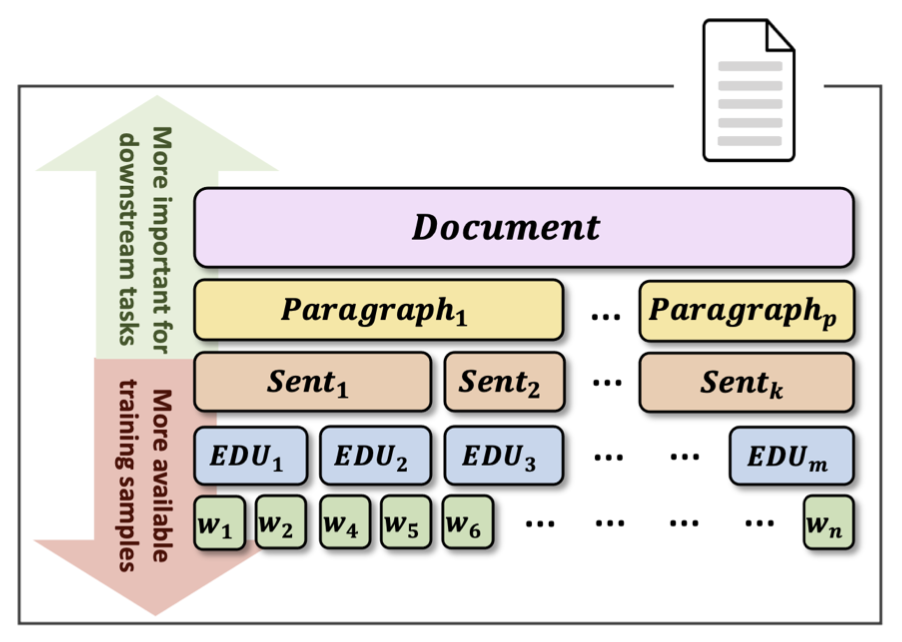
Topic Segmentation to Infer High Level Discourse Structures Improving on our work using sentiment augmented data to infer discourse structures, we target high-level (above-sentence) discourse structures in our AAAI 2022 work on Predicting Above-Sentence Discourse Structure using Distant Supervision from Topic Segmentation. We thereby exploit our top-performing neural topic segmentation model presented in this paper to greedily segment documents, showing that the generated high-level (binary) discourse structures align well with gold-standard discourse annotations, an important factor for many downstream tasks implicitly or explicitly converting constituency trees into dependency representations.
Discourse from Summarization
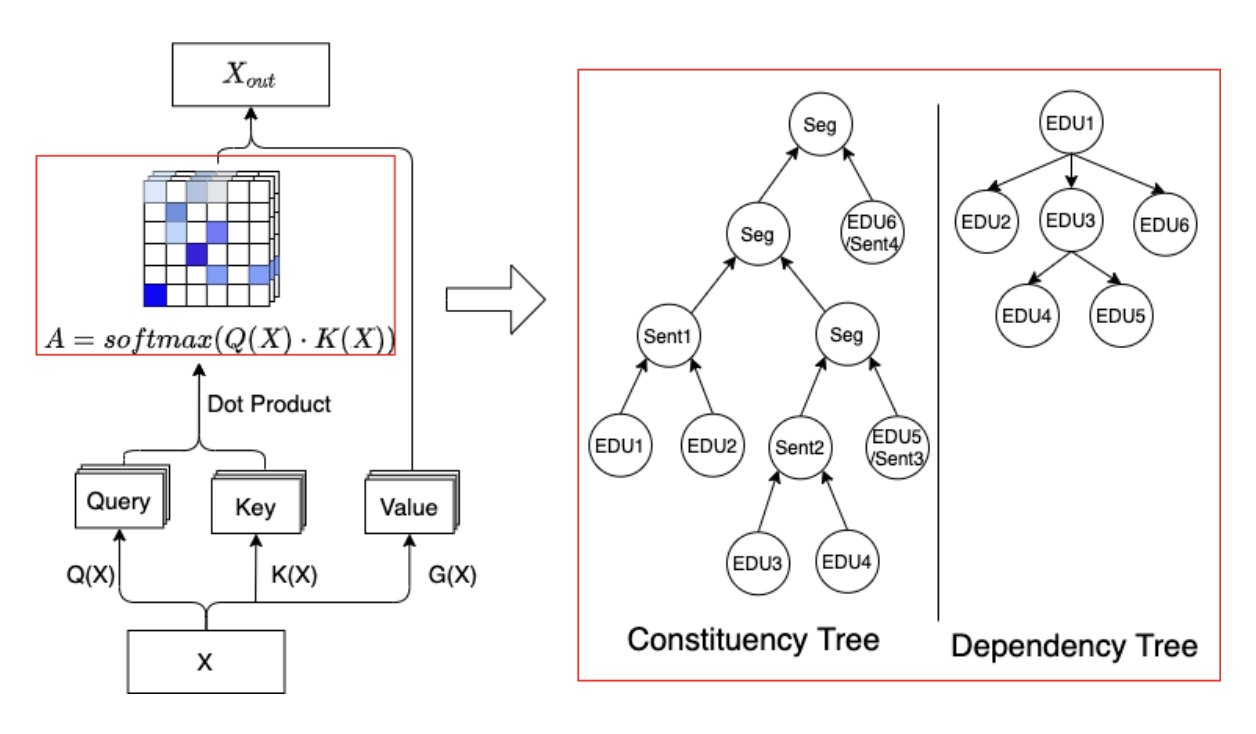
Discourse Inference from Transformer Self-Attention Matrices Extending our work on distantly-supervised discourse parsing, we explore the auxiliary task of summarization, especially focussing on the nuclearity attribute, which has previously been shown to contain importnat information for summarization related tasks. In our NAACL 2021 paper, we show that discourse (dependency) structures can be reasonably inferred using the CKY and Eisner algorithms to extract discourse trees from transformer self-attention matrices, marking an important first step to explore state-of-the-art NLP models for their alignment with discourse information.
Discourse from Tree-style Autoencoders
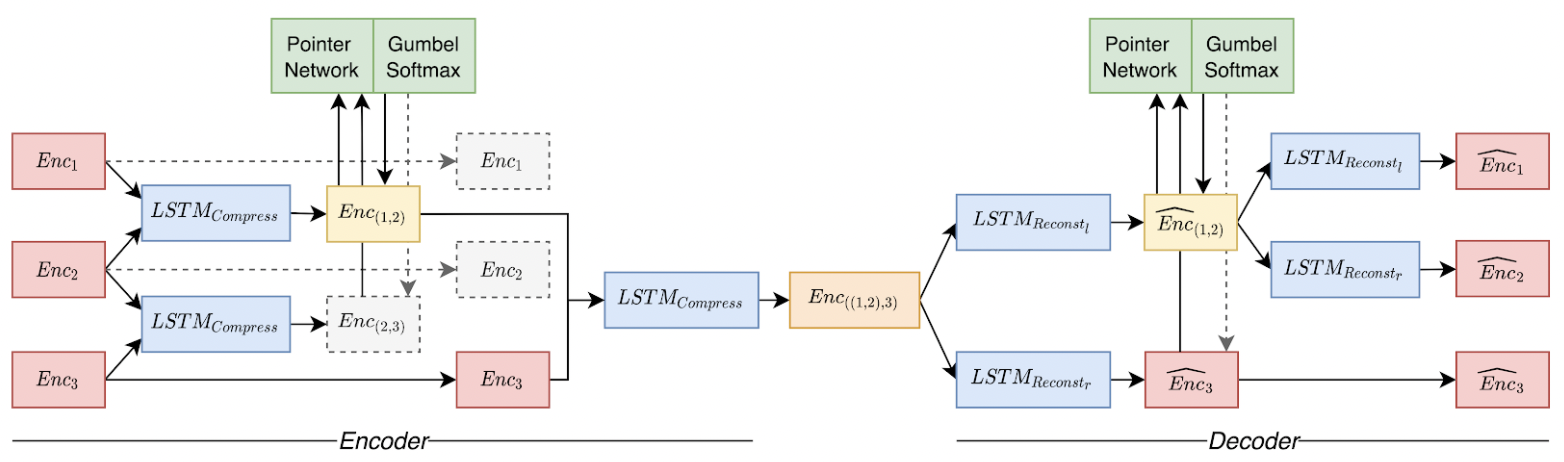
Unsupervised Tree Auto-Encoder In our AAAI 2021 paper on Unsupervised Learning of Discourse Structures using a Tree Autoencoder, we aim to generate discourse structures (without nuclearity and relation labels) from the task of tree-style language modelling. In contrast to many modern approaches interpreting the language modelling task as a sequential problem, we explicitly generate discrete tree structures during training and inference. We show that those tree structures learned purely from existing large-scale datasets can reasonably align with discourse and further also supports important downstream tasks (here: sentiment analysis). While the performance is nowhere close to supervised (or distantly-supervised) models, we show first insights into the value of generating more tree-enabled structures for language modelling, potentially valuable for further research in the future.
W-RST: A weighted Extension of Discourse Theories
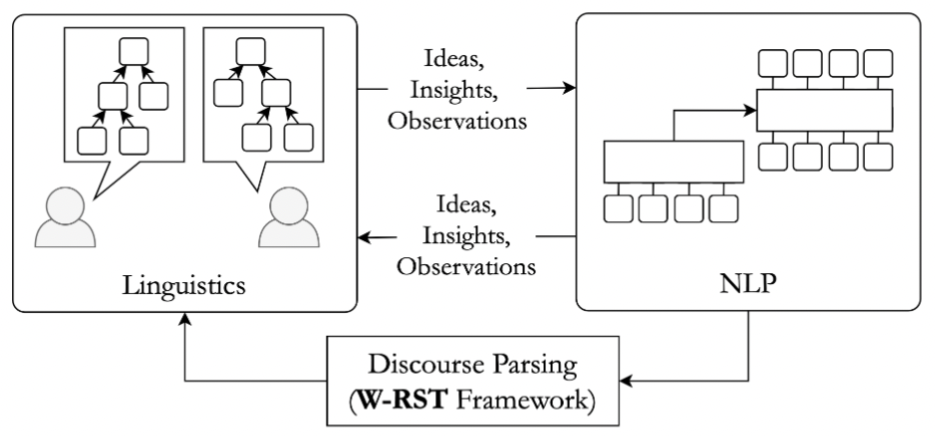
The W-RST framework bridging the gap between Linguistics and NLP In a first attempt to bridge the ever growing gap between (Computational) Linguistics and Natural Language Processing, we propose the Weighted-RST (W-RST) framework at ACL 2021. In this line of work, we explore the usage of readily available real-valued scores in distantly supervised discourse models, namely the MEGA-DT and our NAACL 2021 paper, to generate more fine-grained importance scores between sibling sub-trees (i.e., the RST nuclearity attribute). In our experiments, we show that the weighted RST trees are superior to discourse treuctures with binary nuclearity attributes for most thresholds, and further align well with human annotations.
Supervised Discourse Parsers
Our lab further contributed some of the top-performing, completely supervised discourse parsers to date. With the CODRA discourse parser reaching state-of-the-art performance at the time using an optimal parsing algorithm with two Conditional Random Fields for intra-sentential and multi-sentential parsing.
More recently, our neural discourse parser presented at CODI 2020 based on the shift-reduce paradigm, using SpanBERT and an auxiliary coreference module reached the state-of-the-art performance for RST-style discourse parsing on RST-DT.
-
ConVis
Visual Text Analytics of Conversations (GC Add better pic)
System Overview We have developed visual text analytic systems that tightly integrate interactive visualization with novel text mining and summarization techniques to fulfill information needs of users in exploring conversations (e.g, ConVis, MultiConvis, ConViscope). In this context, we have investigated techniques for interactive (human-in-the-loop) topic modeling. Check out our latest paper
-
Extractive Summarization of Long Documents by Combining Global and Local Context
Check out our work on extractive summarization for long documents!
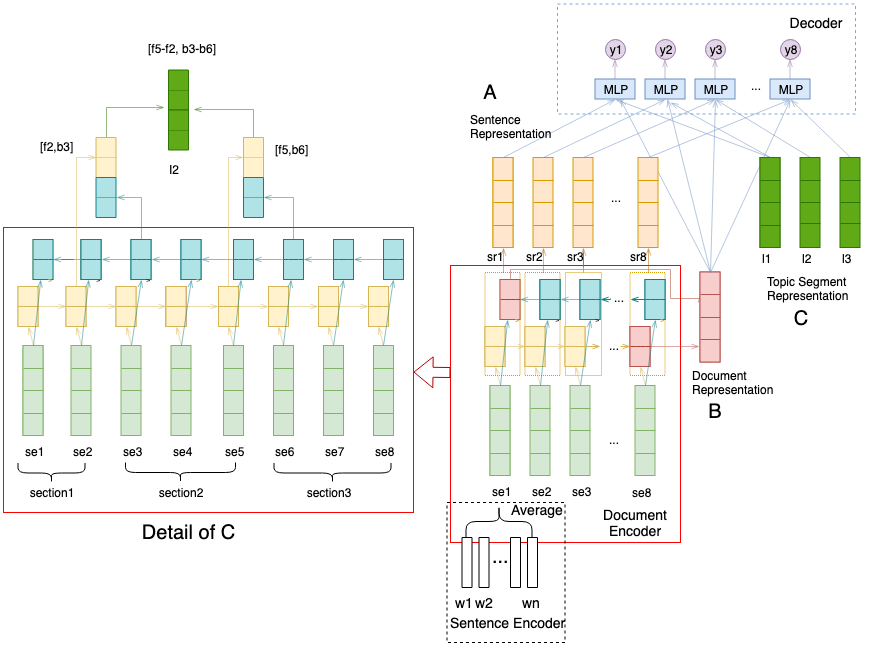
System Overview We propose a novel neural single document extractive summarization model for long documents, incorporating both the global context of the whole document and the local context within the current topic.